Table of Content
Scale the cluster to suit your huge knowledge and analytics workloads through the use of a range of Oracle Cloud Infrastructure compute shapes that assist small check and development clusters to massive manufacturing clusters. Find out tips on how to use machine learning within the cloud with the data you have already got. Search lets you find assets inside a tenancy and important details about your clusters and configuration objects, similar to API keys, metastore configurations, lake configurations. Administrators can set quota insurance policies to enforce restrictions on customers by limiting the assets that they can create.

Learn the means to build an enterprise information lake built-in with an information warehouse. Provides enterprise-grade Hadoop as a service, with end-to-end security, high efficiency, and ease of management and upgradeability. Deployment Guide offers step-by-step directions for download and deployment. Oracle huge information solutions allow analytics teams to investigate all incoming and historic knowledge to generate new insights. Big Data Service is absolutely integrated with OCI Search and helps specific useful resource types. Don't enable customers to create any VM.Standard2.4 OCPUs in the examplecompart compartment.
Take A Getting Started Workshop To Be Taught Big Data Service
Each cluster is automatically provisioned, secured, and shut down to scale back developer workloads. Customers can deploy absolutely managed Hadoop clusters of any dimension or form, then add safety and high availability with a single click on. You can load your personal knowledge into the VM or use the Oracle MoviePlex demo information that is offered. Oracle has created videos, pattern code and hands-on labs based on Oracle MoviePlex that may allow you to learn to develop big data applications using Oracle's huge information platform. All of the collateral used to develop this application is included within the VM. Process, store, and use huge amounts of information as the muse for machine-learning models that allow corporations to develop new business strategies.
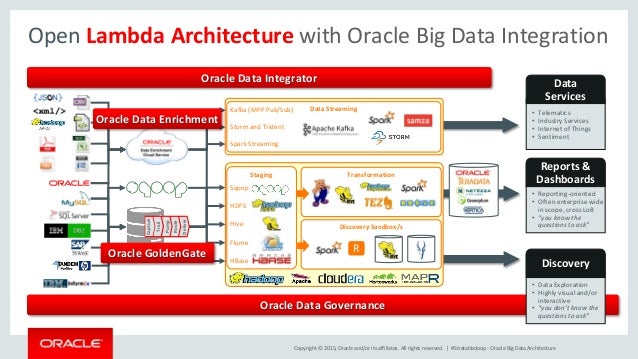
Oracle’s massive knowledge solutions make certain that all data is made obtainable to information science teams, enabling them to construct more reliable and efficient machine studying fashions. Oracle Cloud Infrastructure Data Catalog helps information professionals across the group search, explore, and govern information utilizing a listing of enterprise-wide knowledge assets. It automatically harvests metadata throughout an organization’s information shops and offers a common metastore for data lakes. Data Catalog simplifies the definition of enterprise glossaries and curated details about data assets located in Oracle Cloud Infrastructure and different areas so data consumers can simply find wanted data. Provisions totally configured, safe, highly out there, and dedicated Hadoop and Spark clusters on demand.
Integrate Information Sources Into Enterprise Data Lakes
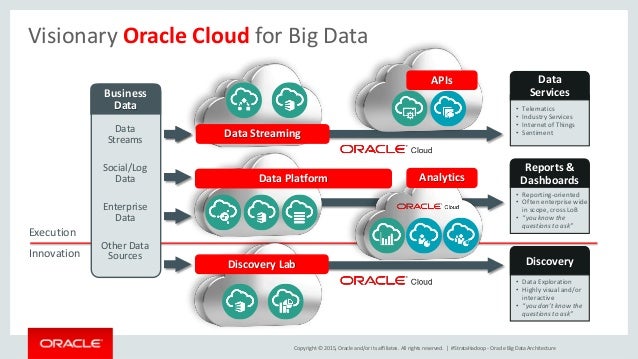
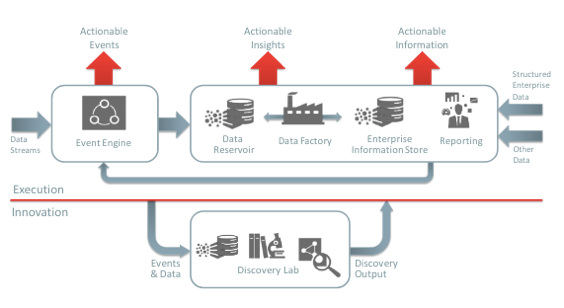
Deploy an entire, built-in answer, together with data administration, knowledge integration, and data science, so analytics groups can maximize the value of enterprise data. Customers ingest any knowledge through batch, streaming, or real-time processes and store it in data warehouses or knowledge lakes as needed. Teams then catalog and apply governance to the data to enable them to use it for analyses, visualizations, and machine studying models.
For details about the OCID format and different ways to establish your assets, see Resource Identifiers. Resources, like most types of assets in Oracle Cloud Infrastructure, have a unique, Oracle-assigned identifier called an Oracle Cloud ID . The REST APIs provide probably the most performance, but require programming experience. API Reference and Endpoints provide endpoint particulars and links to the available API reference paperwork including the Big Data Service API. The OCI CLI offers both quick access and full performance without the necessity for programming. See Big Data Sevice updates for details of parts included in every version of ODH.
The OBE's in this collection give you directions on the way to carry out data mining with Oracle Database 12c, through the use of Oracle Data Miner 4.1. Oracle Data Miner four.1 is included as an extension of Oracle SQL Developer, model 4.1. Oracle Big Data Service is a Hadoop-based knowledge lake to retailer and analyze giant quantities of uncooked customer information. A managed service, Oracle Big Data Service comes with a completely built-in stack that includes both open supply and Oracle value-added instruments that simplify your IT operations. Oracle Big Data Service makes it easier for enterprises to manage, structure, and extract worth from organization-wide knowledge.
This will obtain the newest content to the VM - together with patches and new samples. Search the knowledge base, connect with different users, or contact us. You can view these work requests in a Big Data cluster's element page.
Oracle Helps Cern Use Huge Knowledge To Discover The Universe
A area is a localized geographic space, and an availability area is a number of information facilities situated inside a area. (There's one for a highly-available cluster and one for a non-HA cluster.) A sequence of step-by-step labs guide you thru the method of establishing a easy surroundings and making a small cluster. ODH is constructed from the bottom up, natively built-in into Oracle's information platform. It is absolutely managed, with the identical Hadoop parts you realize and build on at present. ODH is on the market as variations ODH 2.zero, ODH 1.x, and ODH zero.9.
IT groups leverage constant security policies across data warehouses and data lakes. Oracle massive information providers assist information professionals manage, catalog, and process raw information. Oracle presents object storage and Hadoop-based information lakes for persistence, Spark for processing, and analysis through Oracle Cloud SQL or the customer’s analytical software of alternative. Access information in HDFS immediately from the Oracle Database using Oracle SQL Connector for Hadoop.Using SQL Pattern MatchingThis sequence options each OBEs and recorded webcasts.
Attempt Oracle Cloud Free Tier
Organize this data for simple entry and evaluation by analytics groups all through the enterprise. Deploy Oracle massive data services wherever wanted to fulfill buyer data residency and latency requirements. Increase developer productiveness with a completely managed, serverless, Apache Spark cluster that's accessible via APIs.
The OCI Console is an easy-to-use, browser-based interface. Oracle Cloud SQL integration, for analyzing information across Apache Hadoop, Apache Kafka, NoSQL, and object stores using Oracle SQL query language. Cloudera JDBC DriversDownload and set up the Cloudera JDBC drivers to allow Oracle SQL Developer and Data Modeler to connect with Hive. After beginning the VM, double click on the Refresh Samples desktop shortcut.
Get hands-on experience with Oracle’s Always Free providers. Can a automobile firm know extra about your next Mercedes-Benz purchase than you do? Daimler AG, which makes the long-lasting vehicle, makes use of a, combination of AI and predictive analytics to precisely decide when their current customers are ready for one more automotive. See how customers across the globe are utilizing Oracle huge information options to get the most value out of their data.
The capability to create clusters of any size, primarily based on native Oracle Cloud Infrastructure shapes. For instance, you can create small, short-lived clusters in flexible virtual environments, very giant, long-running clusters on dedicated hardware, or any combination between. Oracle Cloud Infrastructure Data Flow is a totally managed Apache Spark service with no infrastructure for customer IT teams to deploy or manage. Data Flow lets builders ship applications quicker because they can concentrate on software development without getting distracted by operations. Limit the variety of BM.DenseIO2.52 OCPUs that users can allocate to providers they create within the testcompartment compartment to twenty. Limit the number of VM.Standard2.four OCPUs that users can allocate to companies they create in the mycompartment compartment to forty.








No comments:
Post a Comment